006 Стратегия релизов (риски, производительность и архитектура)
Недавно снова возник повод сравнить Blue-Green и Canary Deployments. Я решил поднять исследовательскую базу и зафиксировать конкретику по теме.
Ниже - собственные рассуждения, выжимки из работ и ответы на вопросы, которые помогают выбрать соответствующую архитектуру.
Но прежде чем перейти к исследованиям способов релизов, я рассмотрю общий вопрос - как эволюционировали методы разработки программного обеспечения и непрерывной интеграции/развертывания (CI/CD) от монолитных архитектур 1990-х годов к современным решениям на базе контейнеризации и Kubernetes? Эволюция методов разработки и процессов CI/CD прошла долгий путь от медленных ручных релизов к современным автоматизированным облачным решениям. Согласно предоставленным материалам, этот процесс можно разделить на несколько ключевых этапов:
1990-е годы: Эра монолитов и линейной разработки
- В начале 90-х годов программное обеспечение разрабатывалось изолированными командами по строгой линейной модели (от сбора требований до тестирования и поддержки), а развертывание кода выполнялось вручную.
- Архитектура приложений была монолитной. Весь код писался как единый массив, что создавало огромные трудности: изменения от разных команд приходилось ставить в очередь, долго разрешать конфликты при слиянии кода, проводить полное тестирование всего продукта и выпускать приложение единым блоком.
- Для решения проблем сложности дизайна в 1991 году Грэди Буч предложил активнее использовать объектно-ориентированное программирование. Позже, в 1997 году, появилось экстремальное программирование (Extreme Programming), которое заложило основы Agile, внедрив парное программирование, короткие циклы релизов, ревью кода и юнит-тестирование.
2000-е годы: Зарождение Agile, CI и CD
- Для ускорения выпуска ПО бизнес начал активно внедрять гибкие методологии, такие как Scrum и Kanban.
- Настоящим прорывом стало появление инструмента CruiseControl в 2001 году. Он позволил автоматизировать сборку, тестирование и отправку кода в систему контроля версий. Это стало рождением практики непрерывной интеграции (Continuous Integration, CI), позволяющей выявлять конфликты в коде на самых ранних этапах.
- В конце 2000-х годов появились такие инструменты, как Jenkins, которые сделали возможным непрерывное развертывание (Continuous Deployment, CD) в тестовых и рабочих средах. Одновременно с этим стали применяться инструменты управления конфигурациями (Puppet, Chef), обеспечивающие стабильное и повторяемое развертывание.
2010-е годы: Переход к микросервисам и облачным вычислениям
- Начиная с середины 2010-х годов монолитный подход уступил место микросервисной архитектуре. Огромный монолитный код был разбит на небольшие независимые сервисы, каждый из которых можно разрабатывать, тестировать и развертывать отдельно от других.
- Это десятилетие ознаменовалось высоким ростом облачных платформ (AWS, Google Cloud, Azure) и технологий контейнеризации (Docker), которые позволили упаковывать приложения и их зависимости в изолированные образы, гарантируя их стабильную работу в любой среде.
Современный этап: Контейнеризация и Kubernetes
- Традиционные методы развертывания, при которых приложения работали поверх одной операционной системы, часто приводили к сбоям из-за конфликтов общих библиотек и зависимостей. На смену им пришла контейнеризация (например, Docker). Контейнерные движки упаковывают приложение вместе со всеми его зависимостями, библиотеками и бинарными файлами в единый изолированный контейнер. Такие контейнеры можно легко и безопасно переносить с одной машины на другую.
- Для управления большим количеством контейнеров стали применяться платформы оркестрации, такие как Kubernetes. Эта система берет на себя автоматическое масштабирование приложений (создание или удаление подов с контейнерами в зависимости от нагрузки), управление сбоями и маршрутизацию трафика.
- Внедрение Kubernetes в связке с микросервисами позволило современным компаниям реализовать продвинутые стратегии развертывания кода (такие как постепенное или канареечное развертывание), главная цель которых - достижение нулевого времени простоя (zero downtime), минимизация ошибок и полная автоматизация процесса доставки обновлений конечным пользователям.
Далее капнем чуть глубже и рассмотрим вопрос - какие фундаментальные блоки (building blocks) необходимы для построения архитектуры без простоев (модульный дизайн, использование контейнеров, плавное завершение процессов (graceful shutdown), балансировка нагрузки, проверки работоспособности (health checks) и динамическая маршрутизация трафика)?
Для построения надежного конвейера непрерывного развертывания (CI/CD) и достижения нулевого времени простоя (zero downtime) архитектура приложения должна опираться на несколько фундаментальных технических блоков. Эти компоненты работают в связке, обеспечивая высокую доступность и незаметность обновлений для конечных пользователей:
- Модульный дизайн (микросервисная архитектура). В отличие от монолитных систем, где весь код связан в единый блок, микросервисы позволяют разделить приложение на независимые и слабо связанные компоненты. Каждый сервис можно разрабатывать, обновлять, развертывать и масштабировать абсолютно независимо от других, что избавляет от необходимости координировать сложные релизы всего приложения целиком и значительно ускоряет процесс развертывания.
- Контейнеризация. Использование контейнерных сред (например, движка Docker) решает проблему конфликта общих библиотек и зависимостей, которая часто возникает при традиционном развертывании поверх одной операционной системы.
- Плавное завершение процессов (Graceful Shutdown). Критически важный механизм для сохранения целостности данных при обновлении версий. Когда инициируется отключение старого сервера или контейнера, система немедленно перестает принимать новые пользовательские запросы, но не выключается до тех пор, пока полностью не обработает все уже поступившие (in-flight) запросы и корректно не освободит ресурсы. Без этого механизма пользователи столкнутся с потерянными транзакциями и сбоями в обслуживании.
- Балансировка нагрузки (Load Balancer). Балансировщики отвечают за распределение входящего трафика между несколькими серверами или подами. Во время непрерывного развертывания балансировщик позволяет плавно переводить трафик на новую версию приложения, параллельно поддерживая работу старой версии на других серверах. Он также обеспечивает масштабируемость системы, добавляя или удаляя серверы в зависимости от объема нагрузки.
- Проверки работоспособности (Health Checks) и динамическая маршрутизация трафика. Эти функции являются расширением балансировки нагрузки. Балансировщик постоянно опрашивает серверы на предмет их исправности (health checks) и принимает решения о динамической маршрутизации, направляя пользовательские запросы только на полностью рабочие (healthy) узлы. Если новая версия приложения после развертывания не отвечает на запросы, трафик на нее не пойдет. Динамическая маршрутизация также позволяет постепенно (в процентном соотношении) направлять трафик на новые версии для их безопасного тестирования в реальных условиях.
Именно сочетание этих базовых элементов позволяет реализовывать продвинутые стратегии обновлений, такие как постепенное (rolling) или канареечное (canary) развертывание, гарантируя отсутствие простоев.
Сравнительные исследования стратегий
Ссылка на работу. Исследование пяти критических стратегий: Big-Bang, Blue-Green, Rolling, Canary и Ring. Работа связывает инженерные подходы с управлением рисками и пользовательским опытом (UX).
Ссылка на работу. Глубокий разбор того, как Feature Flags (флаги фич) дополняют классические релизы. Приводятся результаты тестов, где аномалии выявлялись на этапе 5% трафика (Canary).
Ссылка на работу. Систематическое сравнение двух самых популярных методов. Анализируются метрики частоты деплоев, время подготовки (lead time), частота сбоев и возможности отката.
Согласно результатам, подход Blue-Green обеспечивает более высокую надежность и мгновенное восстановление, в то время как Canary позволяет быстрее выводить продукт на рынок через постепенный выпуск. Исследование опирается на количественные метрики, такие как частота отказов и время отката, помогая командам выбрать оптимальный путь в зависимости от масштаба проекта.
В чем заключаются базовые принципы и отличия сине-зеленого и канареечного развертываний?
Базовые принципы сине-зеленого развертывания (Blue-Green Deployment):
- Дублирование среды. Используются две идентичные, полностью независимые среды: рабочая («синяя», или Blue) и тестовая/подготовительная («зеленая», или Green).
- Моментальный переход. Новая версия приложения развертывается и полностью тестируется в «зеленой» среде. Как только она признана стабильной, весь пользовательский трафик мгновенно переключается с «синей» среды на «зеленую».
- Быстрый откат. Если после переключения обнаруживается критическая ошибка, трафик можно так же мгновенно перевести обратно на «синюю» среду, которая все еще содержит предыдущую стабильную версию. Это обеспечивает релизы с нулевым временем простоя и высокой надежностью.
Базовые принципы канареечного развертывания (Canary Deployment):
- Поэтапное внедрение. Новая версия ПО выпускается не для всех сразу, а постепенно, начиная с небольшой группы пользователей («канареек»).
- Тестирование в реальном времени. Этот инкрементальный подход позволяет оценить, как обновление ведет себя в реальных условиях эксплуатации.
- Раннее обнаружение проблем. Если у первой группы пользователей возникают ошибки, развертывание останавливается. Это предотвращает масштабные сбои, так как проблема затрагивает лишь малую долю аудитории.
Позволяет ли канареечное развертывание быстрее выявлять и устранять программные ошибки по сравнению с сине-зеленым за счет поэтапного внедрения и получения отзывов от пользователей в реальном времени?
Канареечное развертывание действительно позволяет быстрее выявлять программные ошибки благодаря поэтапному внедрению. При этом подходе новая версия программного обеспечения сначала становится доступной лишь небольшой подгруппе пользователей (так называемым «канарейкам»), что дает возможность в реальном времени оценить влияние обновления и обнаружить проблемы на ранней стадии, до того как они затронут всех пользователей. Однако, если говорить об устранении ошибок и восстановлении работы системы, канареечное развертывание уступасине-зеленому (Blue-Green Deployment) в скорости.
Исследования показывают:
- Время восстановления (Recovery Time). В среднем восстановление при канареечном развертывании занимает 3 минуты, тогда как при сине-зеленом - всего 1,5 минуты.
- Сложность отката. Более долгое восстановление связано с тем, что откат при канареечном подходе происходит постепенно и может требовать большего ручного вмешательства. В то же время сине-зеленое развертывание позволяет мгновенно переключить трафик обратно на стабильную («синюю») среду.
- Операционная нагрузка. Канареечное развертывание сопряжено с более высокими операционными издержками, так как требует тщательного мониторинга, координации нескольких этапов внедрения и максимально быстрой реакции команды на возникающие инциденты.
Таким образом, канареечное развертывание превосходно справляется с быстрым и безопасным обнаружением багов в реальных условиях, но сам процесс возврата системы в стабильное состояние (отката) при этом подходе занимает больше времени и ресурсов по сравнению с сине-зеленой стратегией.
Обойдется ли реализация сине-зеленого развертывания дороже, чем канареечного, из-за необходимости поддерживать дублирующую среду?
С точки зрения затрат на инфраструктуру сине-зеленое развертывание обходится дороже, так как требует полного дублирования среды. Но в исследовании выделяется важный нюанс, который не все просчитывают, касающийся операционных расходов. Несмотря на более высокие затраты на инфраструктуру, сине-зеленое развертывание на практике может оказаться более экономичным в операционном плане. Так как канареечный подход требует:
- Экстенсивного непрерывного мониторинга.
- Сложной координации множества поэтапных раскаток релизов.
- Более высоких трудозатрат ИТ-команды на управление трафиком и контроль каждого этапа.
Поэтому выбор стратегии часто сводится к компромиссу - канареечное развертывание позволяет сэкономить на аппаратных и облачных ресурсах, но сине-зеленое развертывание значительно снижает операционную нагрузку на инженеров.
Технические и архитектурные работы
Ссылка на работу. Исследование методологий релиза в экосистеме Microsoft Azure. Анализируется, как постепенная миграция трафика влияет на профиль риска приложения.
Ссылка на работу. Очень свежая работа про «умные» канареечные релизы. Авторы предлагают архитектуру, которая позволяет безопасно обновлять не только код сервисов, но и схемы баз данных без простоя.
Особое внимание уделяется канареечному развертыванию, для реализации которого предлагается использовать связку Kubernetes, сервисной сетки Istio и инструмента Liquibase. В работе представлена уникальная референсная архитектура, позволяющая одновременно обновлять микросервисы и схемы баз данных без перерывов в обслуживании. Предложенный подход минимизирует риски за счет постепенного переключения трафика и возможности быстрого отката изменений. Итоговое сравнение различных технических сценариев подтверждает, что данная методика обеспечивает высокую доступность и стабильность современных ИТ-систем.
В чем заключаются технические особенности основных методов развертывания в Kubernetes: Recreating (полное воссоздание), Rolling (постепенное), Blue-Green (сине-зеленое) и Canary (канареечное)?
- Recreating Deployment (Полное воссоздание). Этот метод заключается в полной замене существующей версии приложения на новую. Существующие поды (pods) и ресурсы полностью останавливаются, после чего создаются новые поды с обновленной версией сервиса. Это единственный из четырех методов, который вызывает простой (downtime) системы. Длительность простоя зависит от времени, необходимого на отключение старых экземпляров и запуск новых. Метод обычно используется для мажорных релизов с существенными изменениями кода или для приложений, которые технически не поддерживают непрерывное развертывание. Оценка: Высокое время внедрения изменений (Lead time), низкая операционная стоимость (Cost), но низкое качество пользовательского опыта (User Experience) из-за прерывания обслуживания.
- Rolling Deployment (Постепенное развертывание). Позволяет обновлять сервис без прерывания обслуживания клиентов. В файле развертывания задается конфигурация количества создаваемых подов (replica set). При обновлении образа (image) Kubernetes начинает постепенно создавать новые поды и плавно завершать работу старых. Уничтожение старых подов происходит только после получения положительных результатов проверок работоспособности (health checks) новых экземпляров. Оценка: Низкое время внедрения (Lead time), низкая операционная стоимость (Cost) и высокий уровень пользовательского опыта (UX).
- Blue-Green Deployment (Сине-зеленое развертывание). Решает проблему потенциально неудачных релизов, позволяя полностью протестировать новую версию до того, как на нее перейдут пользователи. Создаются **две абсолютно идентичные производственные среды**. «Синяя» (Blue) среда - это текущая рабочая версия, а «Зеленая» (Green) - новая версия, которая развернута параллельно, но пока не принимает реальный трафик. После полного тестирования «Зеленой» среды трафик мгновенно на 100% переключается на нее с помощью балансировщиков нагрузки, маршрутизаторов или обратного прокси. Оценка: Среднее время внедрения (Lead time), высокая операционная стоимость (Cost) и средний уровень пользовательского опыта (UX) (так как скрытые ошибки новой версии могут повлиять сразу на всех пользователей при переключении 100% трафика).
- Canary Deployment (Канареечное развертывание). Сочетает плавность перехода и безопасность тестирования на реальном трафике. Новая версия приложения (canary) развертывается лишь для небольшой, заранее определенной подгруппы пользователей или небольшого процента трафика (например, 10% или 20%). Стабильная версия продолжает обслуживать остальных пользователей. После проверки производительности и стабильности на реальном "канареечном" трафике, нагрузка постепенно (например, 40%, 90%, 100%) переводится на новую версию. Если в новой версии обнаруживаются ошибки, откатиться очень легко - достаточно перенаправить весь трафик обратно на стабильную версию. Это самый безопасный метод с точки зрения минимизации влияния ошибок на всю аудиторию. Оценка: Среднее время внедрения (Lead time), низкая операционная стоимость (Cost) и высокий уровень пользовательского опыта (UX). Согласно исследованиям, именно канареечное развертывание является наиболее перспективным инструментом для предприятий, стремящихся к полному отсутствию простоев.
Почему встроенных возможностей автомасштабирования Kubernetes недостаточно для точного распределения трафика между версиями (например, 90% старой версии и 10% новой), и почему требуется применение open-source инструментов, таких как Istio?
Kubernetes маршрутизация трафика жестко привязана к количеству запущенных экземпляров (реплик) приложения, а не управляется на уровне балансировщика с заданными весами. Из-за изолированности автомасштабаторов настроить точное процентное распределение трафика (например, 90/10) невозможно. Для достижения такого соотношения администраторам пришлось бы вручную поддерживать нужную пропорцию реплик (например, вручную задавать 9 реплик для старой версии и 1 реплику для новой) и постоянно корректировать их при изменении нагрузки, что является трудоемким процессом.
Open-source инструменты, такие как сервисная сетка (service mesh) Istio, решают эту фундаментальную проблему, отделяя (decoupling) логику распределения трафика от количества развернутых реплик. Istio внедряет собственные объекты конфигурации, такие как VirtualService и DestinationRule. С их помощью контроллер на уровне балансировщика нагрузки приложения берет на себя всю тяжелую работу по маршрутизации. Это позволяет направлять ровно 10% трафика на новую версию и 90% на старую на основе заданных весовых коэффициентов (weight-based routing), независимо от того, сколько именно подов (реплик) каждой версии в данный момент запущено и как они автомасштабируются.
Как применять инструмент управления базами данных Liquibase и стратегию "расширения и сжатия" (expand and contract), чтобы одновременно поддерживать старую и новую схемы базы данных в период постепенного перевода трафика на новую версию приложения?
Стратегия «расширения и сжатия» (expand and contract) в связке с инструментом управления версиями баз данных Liquibase решает проблему простоев при обновлении, позволяя старой и новой версиям приложения работать с базой данных одновременно. Это достигается за счет временного сосуществования старой и новой схем БД на период перевода пользовательского трафика.
Техническая реализация этого подхода состоит из следующих элементов и шагов:
1. Интеграция БД и кода приложения. Код микросервиса и наборы изменений схемы БД (changesets) развертываются из единого репозитория, что избавляет от необходимости создавать изолированные конвейеры развертывания для баз данных. Микросервис полностью управляет обновлениями схемы с помощью плагина _Liquibase Maven_. При этом используется специальный конфигуратор Spring, который не позволяет приложению запуститься, если изменения в БД не были успешно применены (это помогает на ранних этапах выявлять ошибки интеграции).
2. Использование «контекстов» Liquibase. Для разделения фаз внедрения применяются «контексты» (contexts) Liquibase. Значение контекста передается в качестве аргумента JVM при запуске микросервиса. Файлы наборов изменений (changesets) в Liquibase предварительно помечаются атрибутами expand (расширение) или contract (сжатие). В зависимости от текущего этапа конвейера, Liquibase выполняет только нужные изменения.
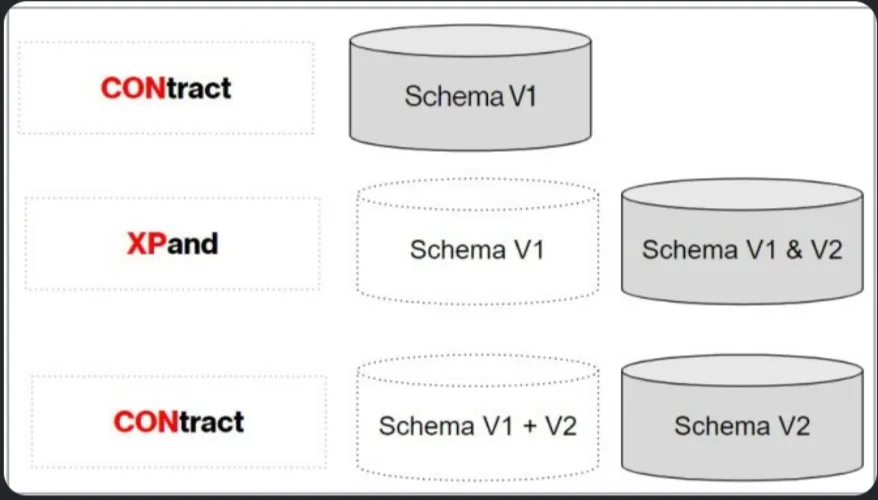
3. Поэтапный процесс развертывания:
- Этап 1: Стабильная работа (CONtract). Изначально в рабочей среде функционирует стабильная версия микросервиса (V1). Работает только схема базы данных версии V1.
- Этап 2: Запуск канареечной версии и «Расширение» (XPand). Выпускается новая версия микросервиса (V2). При ее запуске в контекст Liquibase передается свойство `expand`. На этом этапе Liquibase применяет новые изменения в БД, не удаляя при этом старые структуры таблиц и данных. В результате в базе данных начинают одновременно сосуществовать обе схемы (Schema V1 & V2). Благодаря этому старая версия приложения (V1) продолжает работать без сбоев.
- Этап 3: Постепенный перевод трафика. Трафик пользователей распределяется между версиями V1 и V2 (например, 60% на 40%) с помощью балансировщиков нагрузки и Ingress-контроллеров. Обе версии успешно обслуживаются единой базой данных.
- Этап 4: Полный переход и «Сжатие» (CONtract). После того как версия V2 успешно валидирована и на нее переведено 100% трафика, старая версия V1 выводится из эксплуатации. Новая версия V2 теперь становится "стабильной". При ее окончательном развертывании контекст Liquibase меняется на `contract`. Это запускает финальные наборы изменений, которые выполняют очистку БД и навсегда удаляют старую схему V1, оставляя только схему V2.
-systems.DCI1RFyd_24AxQM.webp)
Данный шаблон позволяет избежать традиционной проблемы классических обновлений, когда БД отключается для накатывания скриптов DDL (Data Definition Language). В случае использования Liquibase пользователи не замечают перехода, а данные остаются согласованными на протяжении всего цикла непрерывного развертывания.
Как выглядит полная эталонная архитектура (reference architecture), объединяющая Istio, Liquibase и балансировщики нагрузки для одновременного обновления как сервисов, так и баз данных без потери пользовательских запросов?
Полная эталонная архитектура (reference architecture) для канареечного развертывания с нулевым временем простоя объединяет возможности оркестрации, управления трафиком и контроля версий баз данных. Эта архитектура позволяет обновлять как код микросервиса, так и схему реляционной базы данных в рамках единой транзакции развертывания без потери пользовательских запросов.
Согласно представленным источникам, такая эталонная архитектура состоит из двух параллельных потоков: управления трафиком приложения и версионирования базы данных. Основные элементы архитектуры включают:
1. Инфраструктура маршрутизации и распределения трафика:
- Входящий трафик (Clients) и Ingress-контроллер. Ingress выступает в роли точки входа и балансировщика нагрузки, принимая пользовательские запросы и управляя распределением трафика между различными версиями приложения.
- Istio Service Mesh. Выполняет роль интеллектуального маршрутизатора. Используя объекты `VirtualService` и `DestinationRules`, Istio обеспечивает маршрутизацию на основе заданных весов (weight-based routing). Именно этот компонент позволяет направить, например, 60% трафика на стабильную версию (V1) и 40% на новую канареечную версию (V2) независимо от количества запущенных экземпляров приложения.
2. Среда выполнения приложения:
- Kubernetes-кластер. Выступает в качестве среды для хостинга приложений, упакованных в контейнеры (поды). В кластере развертываются и одновременно работают поды стабильной (App-V1) и канареечной (App-V2) версий микросервиса.
- Единый репозиторий микросервиса. Код приложения и файлы миграций базы данных (changesets) хранятся в едином репозитории. Развертывание приложения автоматически запускает миграцию БД с помощью встроенного плагина (например, Liquibase Maven), устраняя необходимость в отдельных конвейерах (pipelines) для обновления базы данных. Для дополнительной надежности применяется конфигуратор Spring, который блокирует запуск микросервиса в кластере, если изменения в БД не были успешно выполнены.
3. Инфраструктура управления базой данных:
- Единая База данных. В отличие от традиционных методов, требующих отключения или репликации БД, эта архитектура использует одну базу данных, к которой обращаются обе версии приложения (V1 и V2).
- Управление схемой через Liquibase. Этот инструмент контролирует выполнение изменений в БД, используя концепцию «контекстов» (`expand` - расширение, `contract` - сжатие), которые передаются при запуске приложения.
Систематические обзоры (для широкого контекста)
Ссылка на работу. Фундаментальный обзор 30 различных подходов и инструментов для реализации CI/CD. Поможет понять, как стратегии релизов вписываются в общий жизненный цикл разработки.